# Load libraries used everywherelibrary(tidyverse)library(boot)library(kableExtra)library(tidymodels)library(patchwork)library(mulgar)library(palmerpenguins)library(GGally)library(tourr)library(MASS)library(discrim)library(classifly)library(detourr)library(crosstalk)library(plotly)library(viridis)library(colorspace)library(conflicted)library(tidyverse)library(randomForest)library(vip) # Variable importanceconflicts_prefer(dplyr::filter)conflicts_prefer(dplyr::select)conflicts_prefer(dplyr::slice)conflicts_prefer(palmerpenguins::penguins)conflicts_prefer(viridis::viridis_pal)
Project Synopsis
Water is a scarce commodity in many parts of the world. Accurately predicting its availability while reducing the need to routinely check would enable lower costs in monitoring that might be better allocated to creating new water resources. Therefore, the aim of this project is to create the best machine learning model for predicting the availability of water.
This challenge is motivated by an analysis by Julia Silge “Predict availability in #TidyTuesday water sources with random forest models”. The data is downloaded from https://www.waterpointdata.org and represents a subset from a region in Africa. The data has been cleaned, with missing values (small number) imputed, and only reliable variables included.
As part of the kaggle competition, the files provided are:
water-train.csv: the training set of data
water-test.csv: the test set, with no labels, that you need to predict the response variable status_id.
sample-submissions.csv: the format of the data that you need to use to make a submission to kaggle.
Note that for the purposes of this competition, the spatial coordinates have been manipulated, as to disguise the actual locations of water points from competitors.
Exploratory Data Analysis
Response Variable
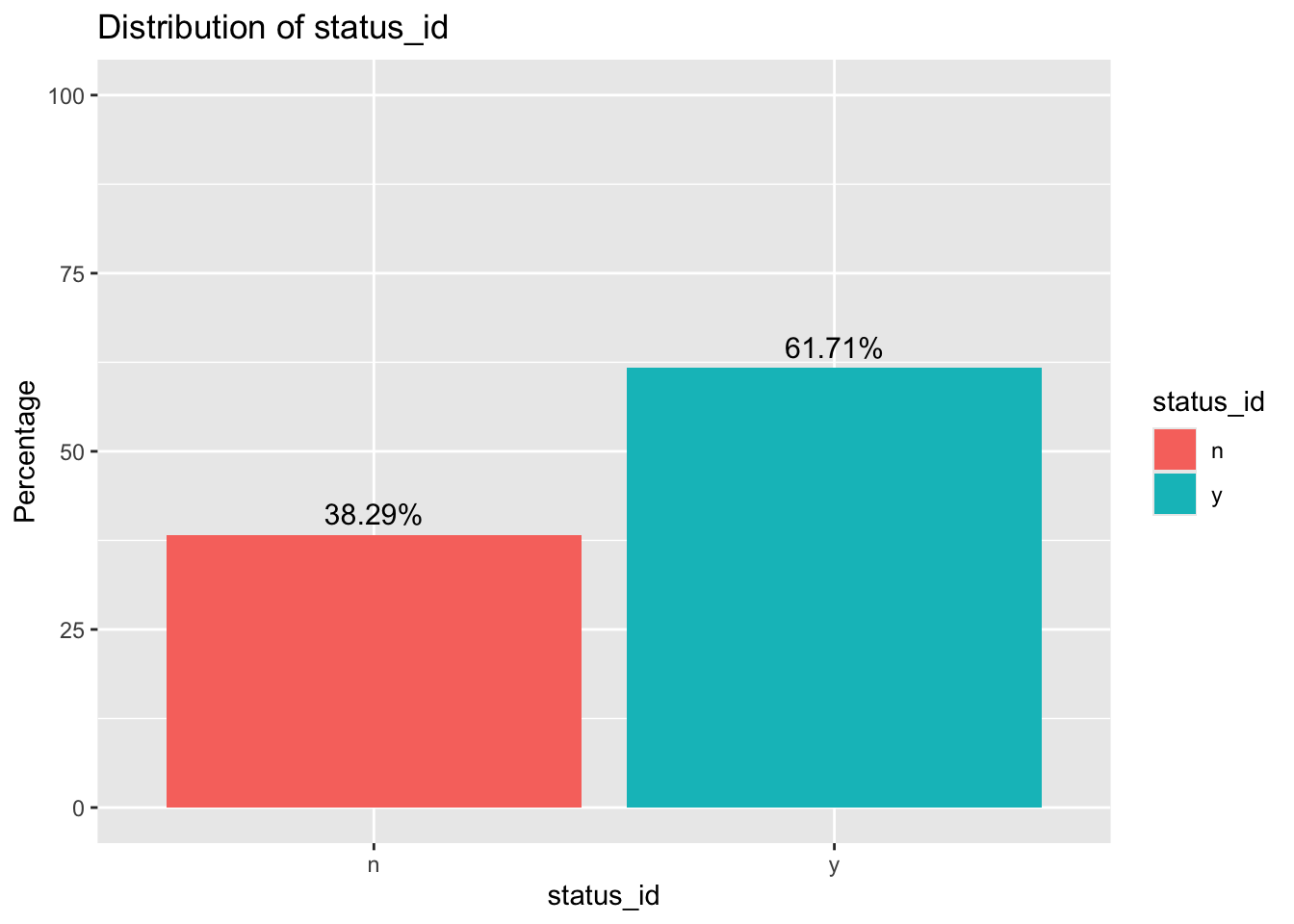
To understand the data that we are working with, we will consider the distribution of our response variables, status_id, where y denotes the existence of water, and n denotes the absence of water.
One key point to note is the unbalanced nature of the data. This is an important aspect of the data to note, and may influence the way that we tune the variables.
Explanatory Variables
Next, we examine the explanatory variables that we can use to model the data, and gain an udnerstanding them.
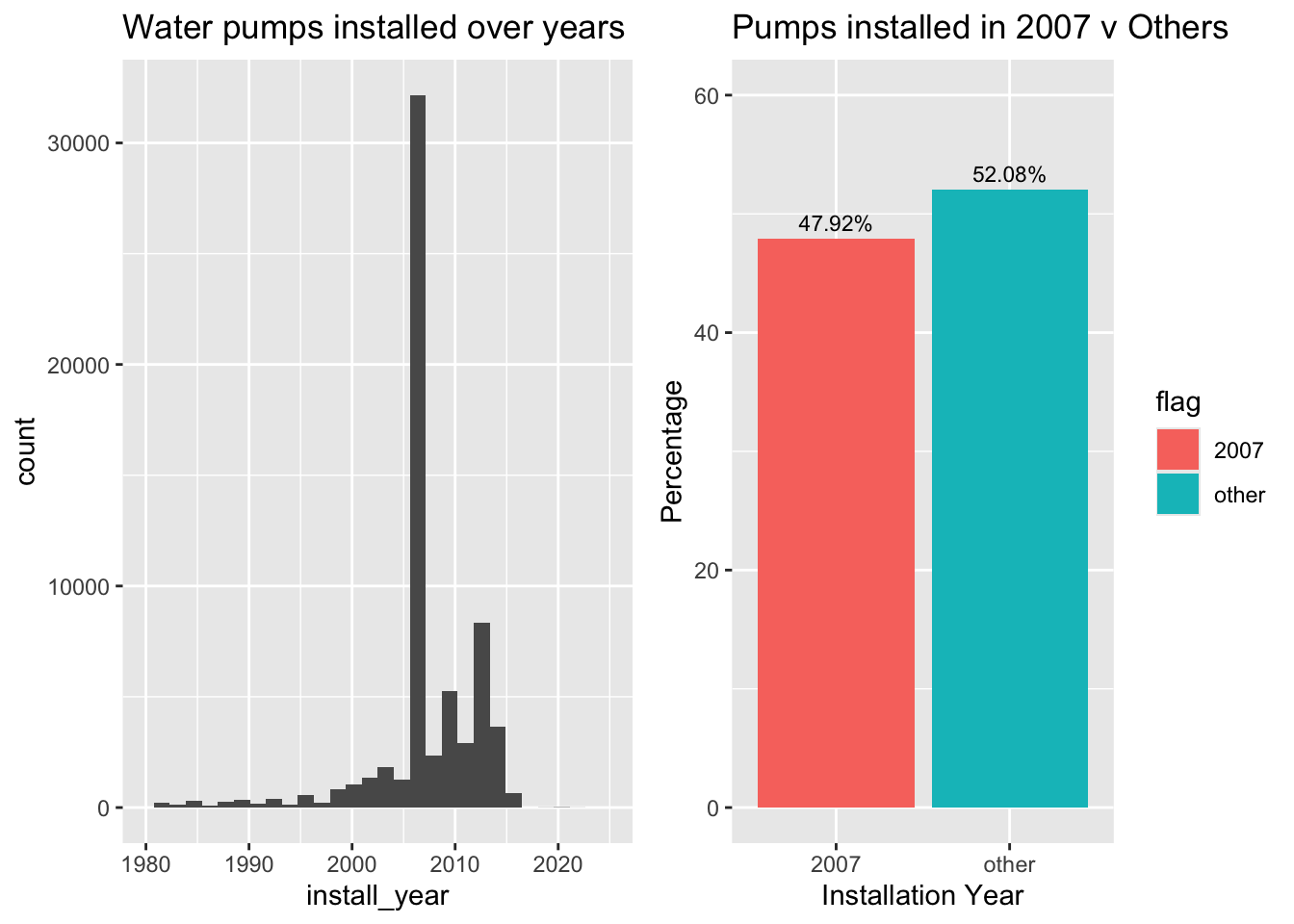
Interestingly, from a time period between 1980 to 2025, almost half of all water pumps were installed in 2007. This may have been due to policy reforms at the time, or errors in data entry. Regardless, some level of scrutiny should be held. In the case of constructing a purely predictive model, by observation, this feature may improve predictive capabilities, as 2007 records (especially when there may have been policy changes) may differ from water pumps installed in other years. However, to truly evaluate variable importance, we would need to actually construct the models and extract the importance. (For example, a mean decrease gini value from a random forest)
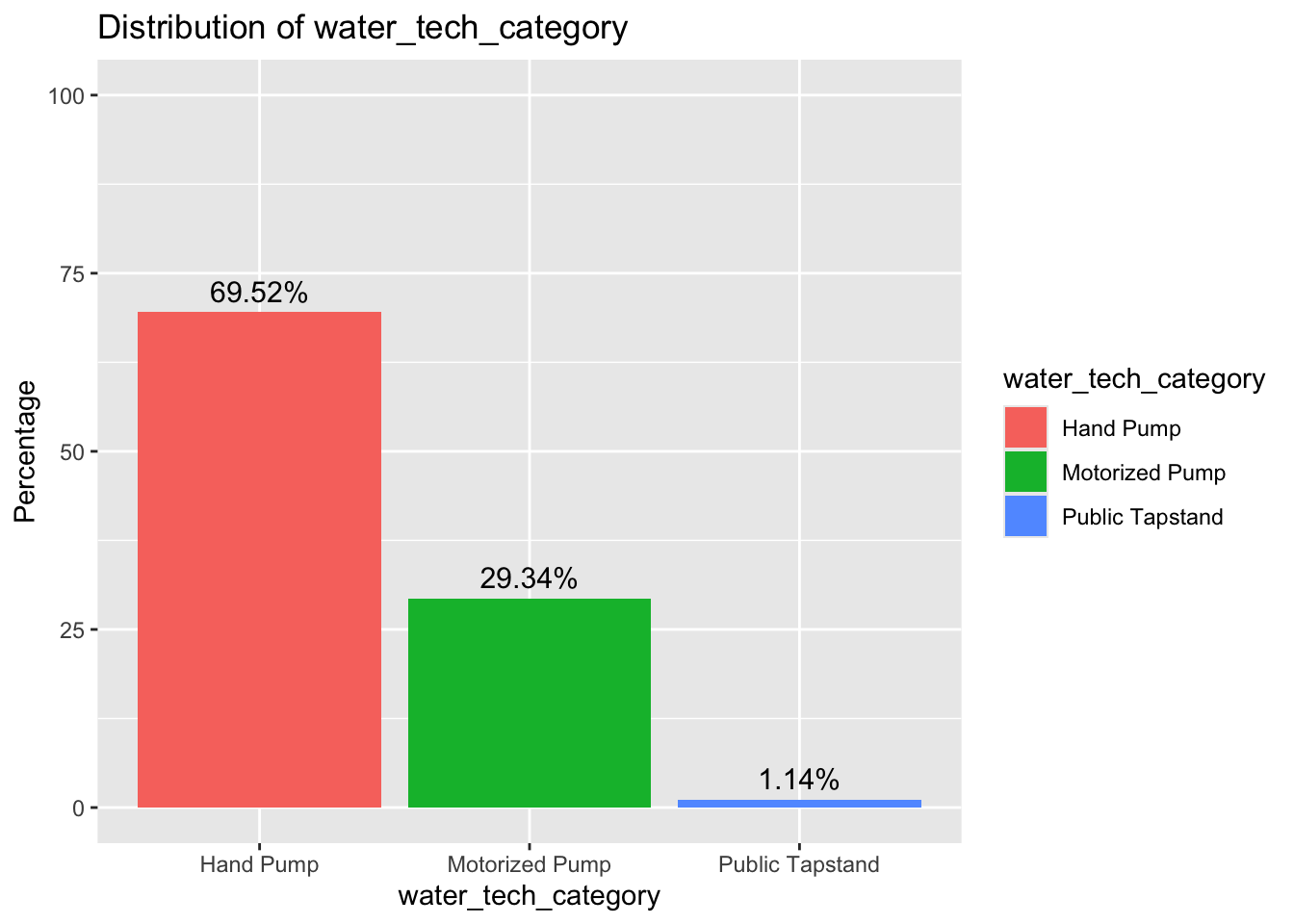
So, what about the actual type of water pump used? It would be interesting to evaluate whether the type of water pump used influences water availability or not.
Geospatial Analysis
Next, knowing that we are working with water availability in a certain region of the world, it would be interesting to use some basic geospatial analytics to determine whether there are particular areas with an abundance of water or not.
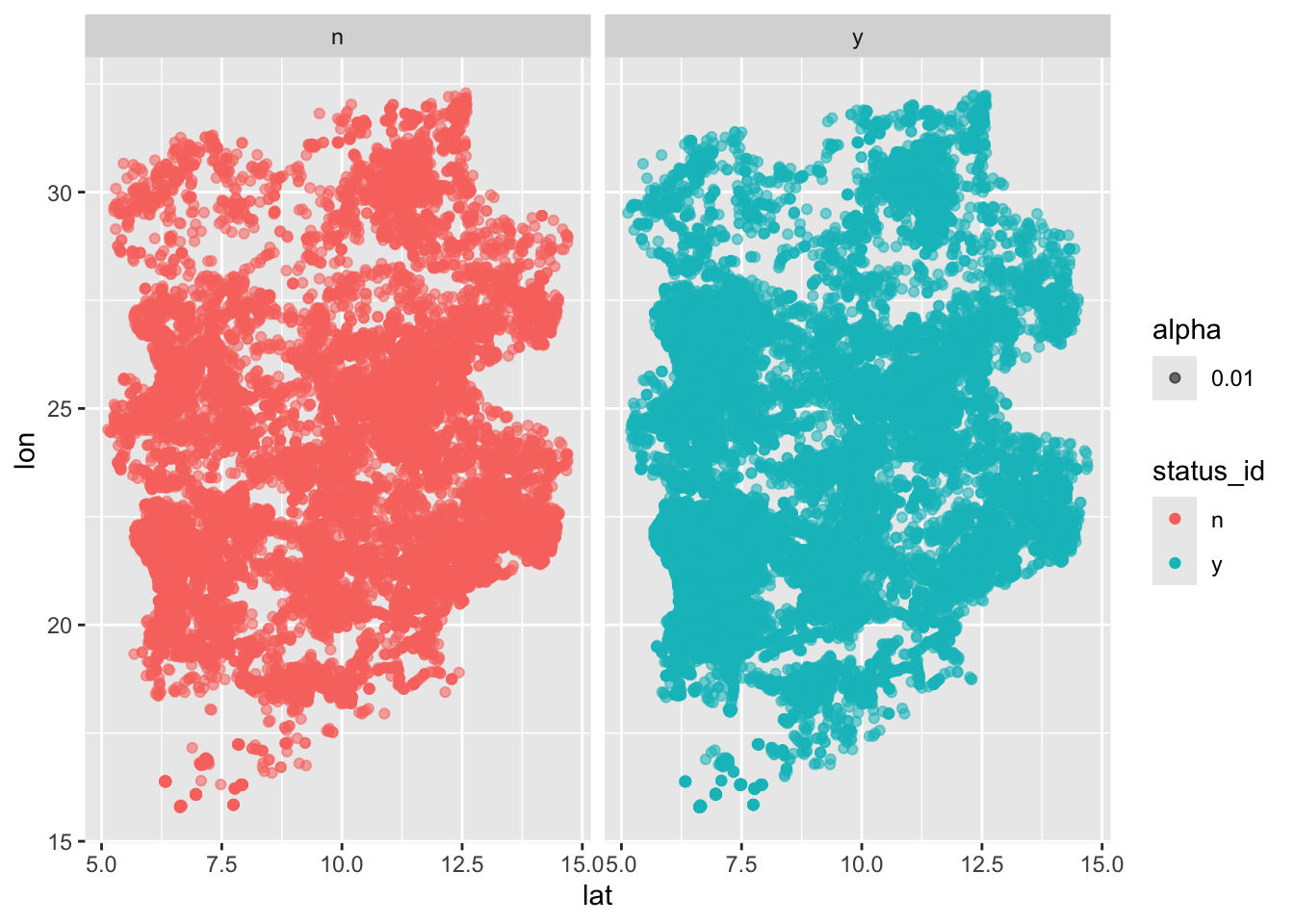
An initial plot shows an almost identical distribution between areas with and without water. Does this mean that there is no relation between location and water availability?
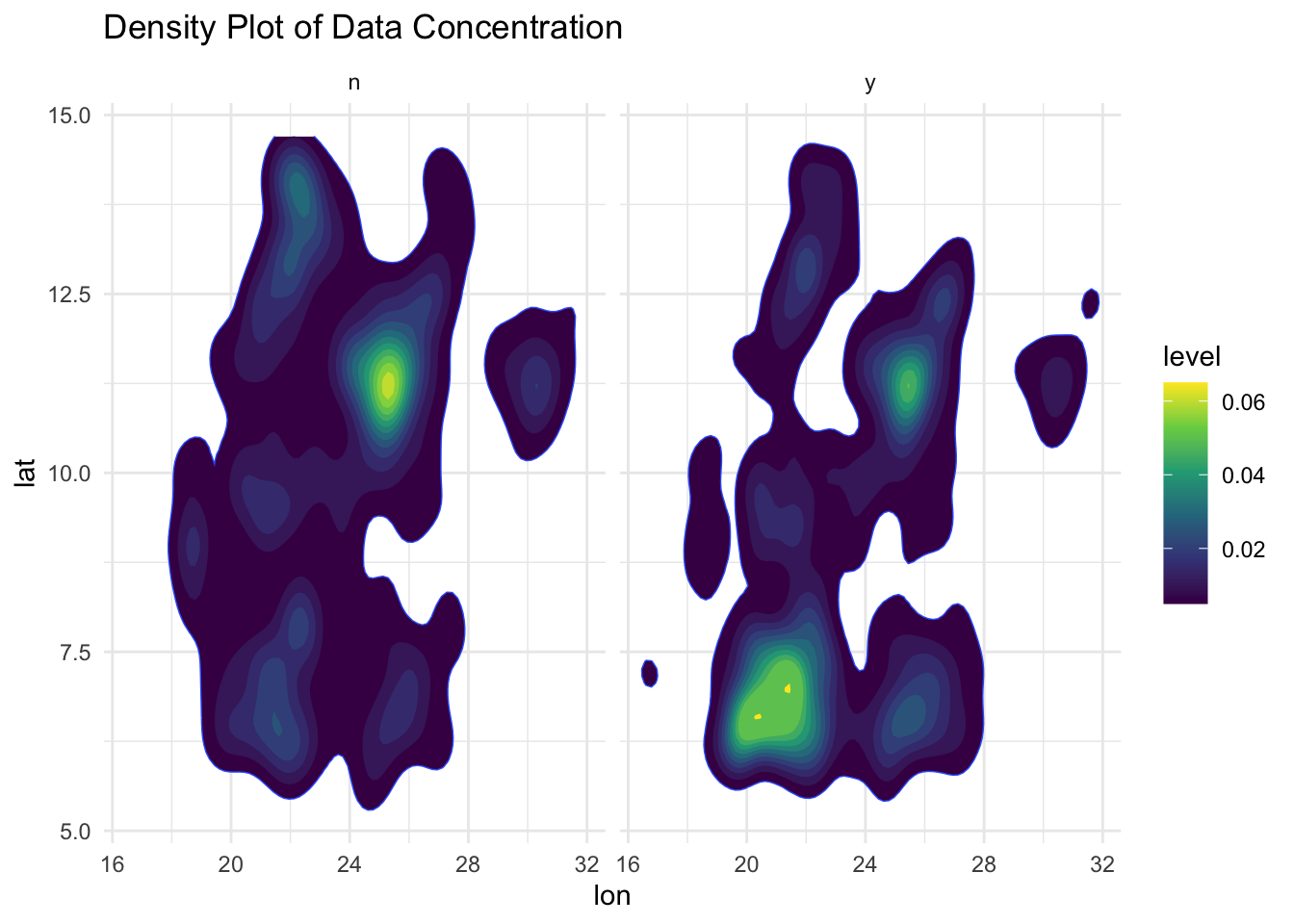
Not quite. What would be worth examining, is where the points might be concentrated with a density plot. For example, consider whether a particular region is particularly dry, and may have scarcer sources of water?
Using a density plot, we indeed begin to see the influences of location on water availability. In particular, it appears that regions where water is more scarce, tends to exist in the more Northern Regions. On the other hand, regions where water seems more abundant, is concentrated towards the Southern regions. This separation appears to suggest that latitude and logitude, will indeed, be quite important in helping us to predict water availability.
For reference on a real world map, water availability and their respective densities can be seen in the leaflet plot below.
Creating the Predictive Models
Pre-processing
The variable report_date is given as a date object, so we will extract the year and month using the lubridate package.
Missing values have been imputed.
Only reliable variables are currently being used in the dataset.
Standardisation will be applied to the data set for running algorithms such as: Linear Discriminant Analysis (LDA) or Logistic Regression. It will not be applied when working with tree based classifiers such as: Random Forest, Decision Trees, Boosted Tree.
library(lubridate)library(kableExtra)## Extract out the date object.water <-read_csv("data/water_train.csv") |>mutate(status_id =factor(status_id)) water <- water |>bind_cols(report_year =year(ymd(water$report_date)), # Get the report yearreport_month =as.character(month(ymd(water$report_date))),report_day =as.character(wday(ymd(water$report_date))) ) |>select(-report_date)## Repeat for testingwater_test <-read_csv("data/water_test.csv")water_test <- water_test |>bind_cols(report_year =year(ymd(water_test$report_date)), # Get the report yearreport_month =as.character(month(ymd(water_test$report_date))),report_day =as.character(wday(ymd(water_test$report_date))) ) |>select(-report_date)
Experimentation with various models
For experimentation of models, I will need a method for testing the accuracies of my model. To this end, I will create a training and testing dataset of my own, using stratified sampling to ensure a balanced train and test split.
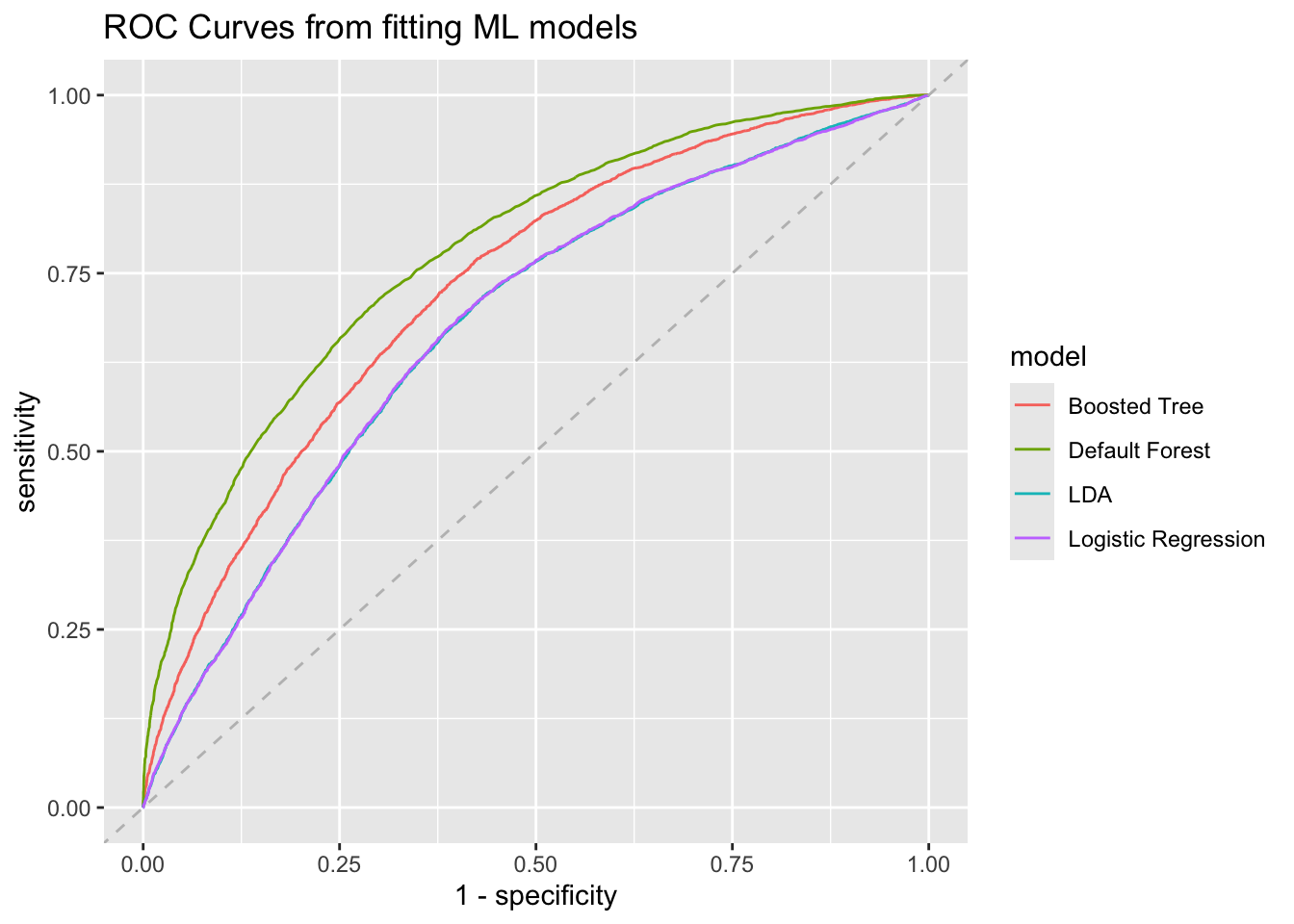
One of the ways I decided on which model to fit, was to compare the ROC curves of each default model, to set a baseline for which model appears to be performing best. Observe that the Default Random Forest has the highest sensitivity for each value of 1-specificity. This indicates to us that, without fine-tuning, the random forest is currently the best performing model, with the highest true positive rate for each false negative rate.
Note that this was relatively surprising. Since there are not distinct separations in the data that we are working with, my initial assumption was that the boosted tree model would perform quite well, especially given that the boosted tree uses a learning parameter to be able to classify difficult observations.
In this case, in future experimentation, it might be worth conducting a comparison of models, after fine-tuning to see if the results would differ. Fine Tuning could be conducted via:
Using the tidy model framework to fit the models, up the hyperparameters to tune for each model. For example, for the random forest, it was ‘trees’, which was the number of trees contained in the ensemble, and ‘mtry’, which was the number of predictors that would be randomly sampled at each split when creating the tree models.
One can use the default 10 fold cross validation to setup training sets to tune on.
Create a grid of values, of each hyper parameter value to experiment with.
Finally, return the values of the hyperparameters that give the highest average accuracy and plot a ROC curve.
Of course, the caveat is that on such a large data set, it would be extremely computationally expensive and time consuming to train so many models. Therefore, for the purposes of this competition, I will simply use the simpler alternative, of tuning the best default model based on the ROC curve, which is the Random Forest.
Final Model
The following code is the final model of the Random Forest that was tuned, and submitted to the competition.
Note that the final model was trained on the entire training set. In this instance, I decided to show the accuracy measures (and balanced accuracies due to the imbalance of the response variables), so I used s.water_train and s.water_test for demonstrative purposes.
For Tuning, I used class weights to adjust the inbalance in response variables, and set different cutoff values for confidence prediction.
Call:
randomForest(formula = status_id ~ ., data = s.water_train[, -1], weights = n_wt, cutoff = c(k, 1 - k))
Type of random forest: classification
Number of trees: 500
No. of variables tried at each split: 4
OOB estimate of error rate: 29.09%
Confusion matrix:
n y class.error
n 12706 5963 0.3194065
y 8223 21866 0.2732892
p_ts_pred <- s.water_test |>mutate(pstatus_id =predict(rf_fit, s.water_test, type ="response")) |>bind_cols(predict(rf_fit, s.water_test, type ="prob"))p_ts_pred |>count(status_id, pstatus_id) |>group_by(status_id) |>mutate(Accuracy = n[status_id == pstatus_id]/sum(n)) |>pivot_wider(names_from ="pstatus_id", values_from = n, values_fill =0) |>select(status_id, n, y, Accuracy) |># kable stylingkable(caption ="Tuned Random Forest - Confusion matrix", digits =3,align ="r") |>kable_styling(full_width = T)
# Create final model n_wt <- ifelse(water$status_id == 'n',# 1.8, 1) k = 0.6## set.seed(15) rf_fit <- randomForest(status_id ~ ., data## = s.water_train[,-1], weights=n_wt, cutoff = c(k, 1-k) )## rf_fit# Write test set predictions into a CSV file. water_ts_pred# <- water_test |> bind_cols(predict(rf_fit,# newdata=water_test, type='prob')) |> mutate(pstatus_id =# predict(rf_fit, newdata=water_test, type='response'))# write_csv(water_ts_pred[,c('ID', 'pstatus_id')],# file='final_test.csv')
Conclusions and Remarks
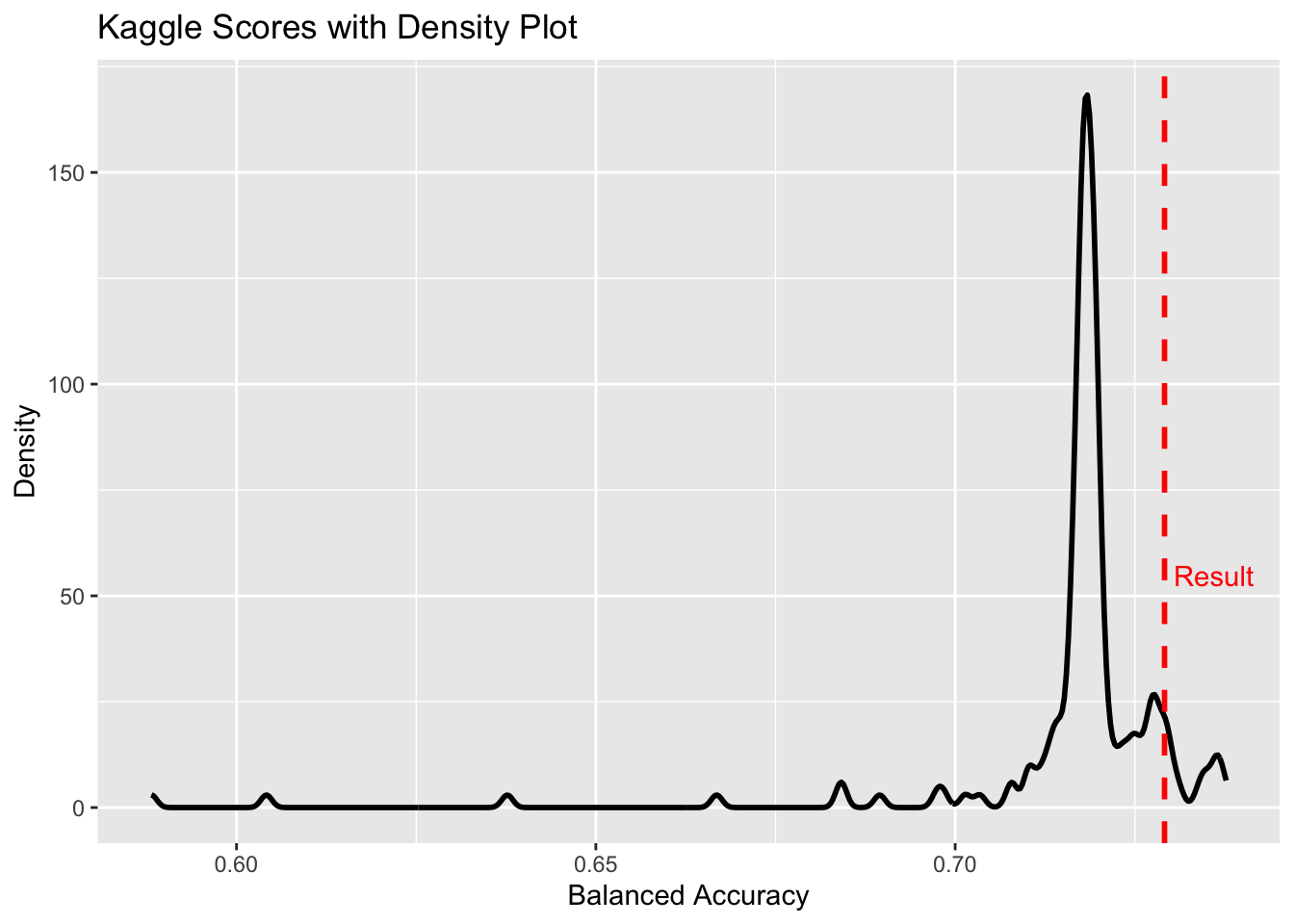
So how does the model perform in this kaggle competition? The results of the fine-tuned Random Forest ends up placing 15th out of 174 contestants, ranking the balanced accuracy of the model in the top 10% of results.